PointNet
CVPR2017《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》
在线介绍:http://stanford.edu/~rqi/pointnet/
paper下载:点击这里
简介
提出了一种新型的处理点云数据的深度学习模型-PointNet,并验证了它能够用于点云数据的多种认知任务,如分类、语义分割和目标识别。
- 共享多层感知机(Shared MLP) + max pool(置换不变性),逐级映射到高层表示
- 刚体变换(包括平移、旋转、反转): 增加T-net(transform net), 将输入的三维点云进行变形,得到规范的数据,能够映射到高维
解决问题
第一次直接在三维点云数据上建立深度学习模型,处理point cloud的数据无序性?。
思想
学习每个点的空间编码,然后利用对称函数把所有单独的点特征聚集成一个全局点云标记特征。
网络有两个亮点:
- 空间变换网络解决旋转问题
三维的STN可以通过学习点云本身的位置信息学习到一个最有利于网络进行分类或分割的DxD旋转矩阵(D代表特征维度,pointnet中D采用3和64)。至于其中的原理,我的理解是,通过控制最后的loss来对变换矩阵进行调整,pointnet并不关心最后真正做了什么变换,只要有利于最后的结果都可以。pointnet采用了两次STN,第一次input transform是对空间中点云进行调整,直观上理解是旋转出一个更有利于分类或分割的角度,比如把物体转到正面;第二次feature transform是对提取出的64维特征进行对齐,即在特征层面对点云进行变换。 - maxpooling解决无序性问题
网络对每个点进行了一定程度的特征提取之后,max pooling可以对点云的整体提取出global feature。
网络设计
对称设计: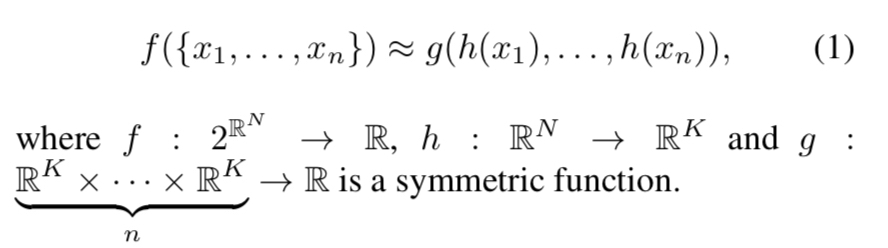
通过一个多层感知机网络近似h函数,再用g对称函数。
该网络通过使用MaxPooling作为对称函数设计来处理点云模型的无序性的,也就是说无论输入的顺序是怎样的,maxpooling都会输出相同的结果。对称函数就是类似自然数加法那样的操作,调换输入顺序输出不变。
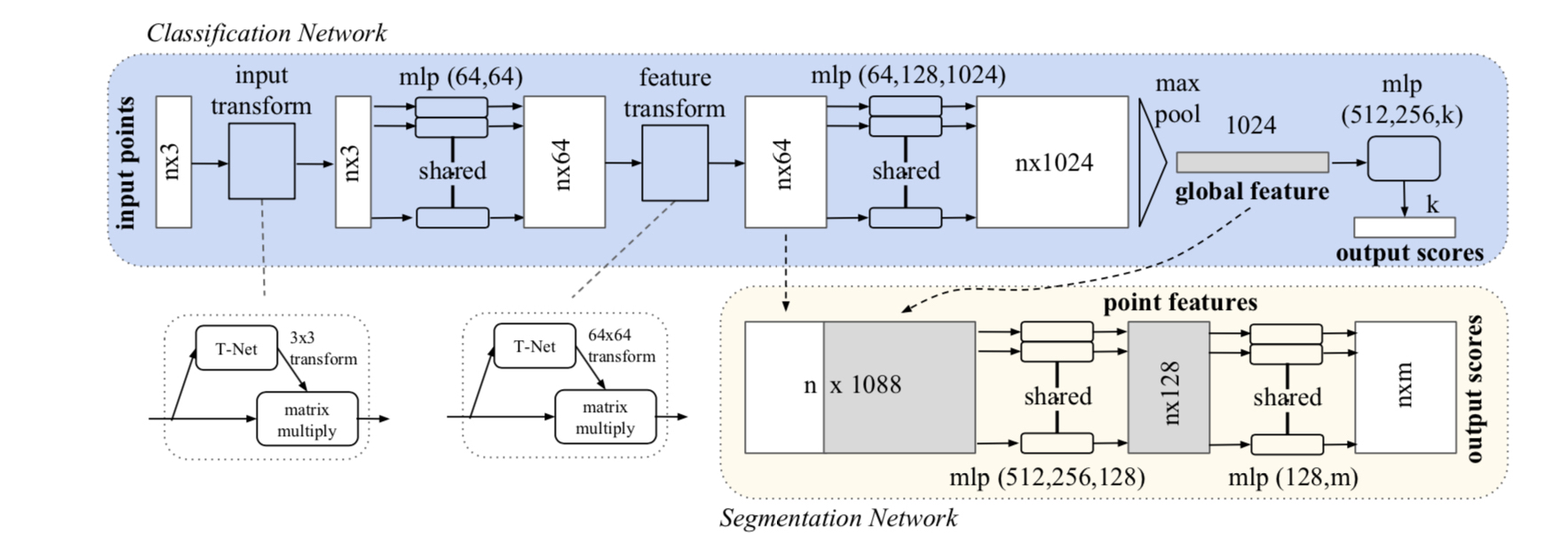
上图中蓝色部分是分类网络,黄色部分是分割网络。分割网络需要cancat global features和local features。(但实际上local features并没有充分地提取局部特征,例如密度表征等,所以后来才提出了其改进版PointNet++,但速度更慢)
其中,mlp是通过共享权重的卷积实现的,第一层卷积核大小是1x3(因为每个点的维度是xyz),之后的每一层卷积核大小都是1x1。即特征提取层只是把每个点连接起来而已。经过两个空间变换网络和两个mlp之后,对每一个点提取1024维特征,经过maxpool变成1x1024的全局特征。再经过一个mlp(代码中运用全连接)得到k个score。分类网络最后接的loss是softmax。
网络结构中,两处用到了STN网络。stn生成仿射矩阵后对每个points都施加相同的仿射变换,不同sample的仿射矩阵不一样,都需要用stn网络计算出来。
为什么用64x64和64x128x1024的感知机?
实验结果
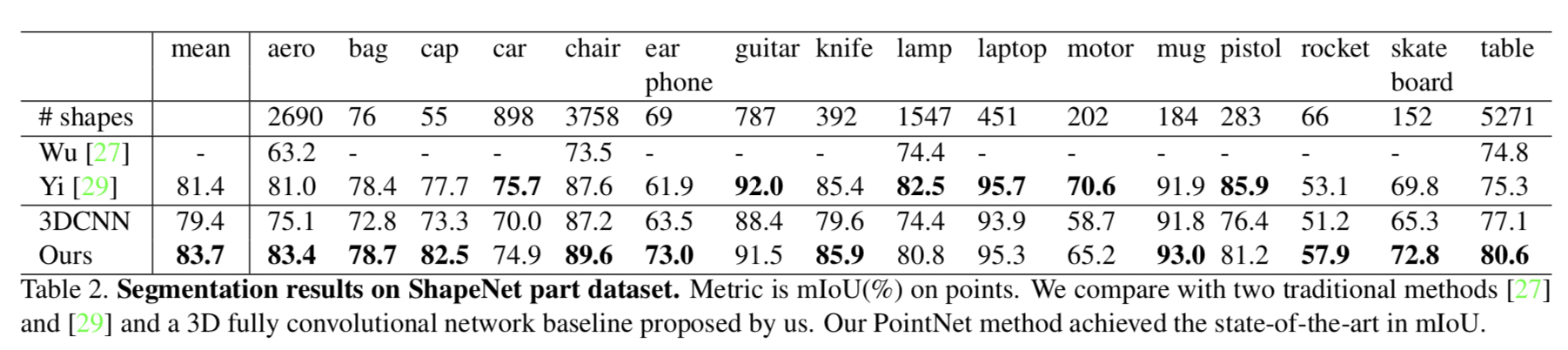
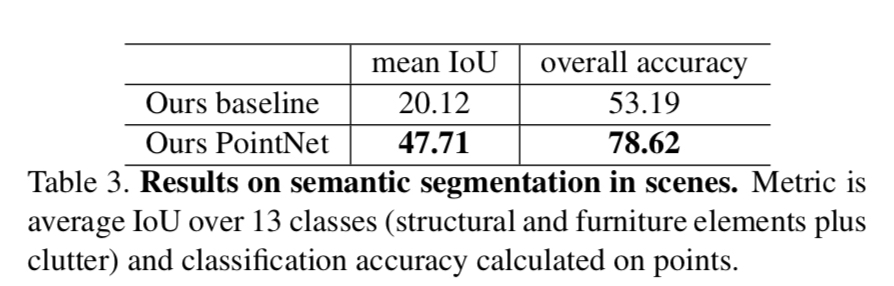
不足:很容易想到的一点就是Pointnet的大部分或说几乎全部的处理都是针对单个采样点的,无论提多么精细的feature都是针对某一个采样点的,而整合所有采样点特征的网络只有那个maxpooling,没错,甚至连可训练的变量都没有,只有一个maxpool。因此,网络对模型局部信息的提取能力远不如卷积神经网络来的那么solid。
Note
Q: T-Net在网络结构中起的本质作用是什么?需要预训练吗?
A: T-Net 是一个预测特征空间变换矩阵的子网络,它从输入数据中学习出与特征空间维度一致的变换矩阵,然后用这个变换矩阵与原始数据向乘,实现对输入特征空间的变换操作,使得后续的每一个点都与输入数据中的每一个点都有关系。通过这样的数据融合,实现对原始点云数据包含特征的逐级抽象
PointNet++
NIPS2017 《PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space》
project page: http://stanford/edu/~rqi/pointnet2/
paper source: http://papers.nips.cc/paper/7095-pointnet-deep-hierarchical-feature-learning-on-point-sets-in-a-metric-space
简介
在PointNet的基础上,模仿CNN卷积的特点(在较低水平,神经元有较小的感受野,而在较高水平,具有较大的感受野),通过分层特征提取来利用local structure。
通过利用度量空间距离,本文的网络能够学习到更大的上下文规模的局部特征(local features)。
采样的点云集合通常有不同的密度,作者提出了新的集合学习层去自适应地结合多尺度特征。
结果
特征表达更加高效、稳健,但是计算代价高且慢(FPS和MSG部分慢?)。
问题
- How to generate the partitioning of the point set(如何划分点集)
定义每个分区为一个有质心和规模的邻域球,质心由FPS(Farthest Point Sampling)进行选择, - How to abstract sets of points or local features through feature learner(如何通过feature learner抽象出点集和local features)
局部邻域球(local neighborhood ball)进行了多尺度的邻域特征提取,在训练期间辅助随机输入丢失,网络自适应地加权在不同尺度下检测的模式并组合多尺度特征。
思考?: CNN中确定局部子集规模(local partition scale)的是kernel size的大小,用越小的kernel,CNN的效果会更好(《Rethinking the Inception Architecture for Computer Vision》中提出,可以用2个连续的3x3卷积层代替单个5x5卷积层,保持感受野范围的同时又减少了参数量)。但是点集上的实验给了反证,因为太少的点采样效果不好。
TODO:能否将划分子集的网络层加深呢?
思想
采用了分层结构来处理局部特征(fine-grained patterns)
在原PointNet中,对于part segmentation以及scene semantic sparsing,即需要得到每个点的得分时,处理办法是直接将点特征与全局特征结合到一块进行处理,忽略了局部特征这一中间步骤,例如在一个场景中,我们先识别出椅子是椅子,桌子是桌子等这些局部特征。
是否在最终对每个点进行分类时,是否会更加准确呢?
所以PointNet++采用了分层结构用于处理局部特征,可以更好地处理fine-grained patterns:- 根据小的邻域提取捕捉几何结构的local features
- 将local features分组到更大的单元去进行处理,去产生high level features。
在网络结构中加入密度适应(density)使得分割更加准确合理
点云数据的一个特征是数据密度不同,体现出近多远少等问题,而在密度不同的情况下,使用统一的模板处理这些数据显然是不对的,针对稀疏点云训练的模型可能无法识别细粒度的局部结构。因此PointNet++的作者提出了密度适应的网络结构。
网络设计
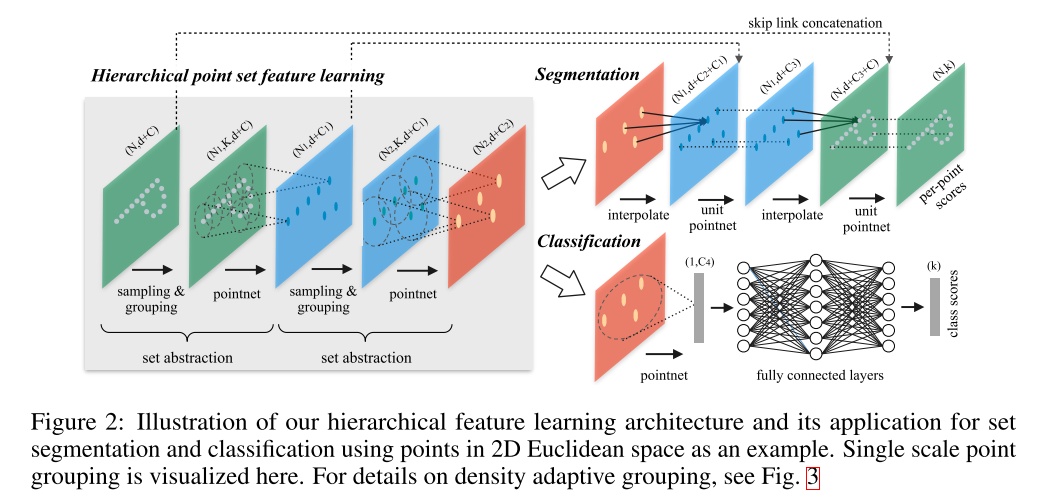
层次点集特征学习可以同时用来做分割和分类工作,上图可视化了单尺度集群方法。
1. 局部特征提取:
PointNet++由一些连续的set abstraction部分分层抽取特征,每个set abstraction部分分为三部分:采样层Sampling layer, 分组层Grouping layer和特征提取层PointNet layer。
采样层用递归式的FPS,从输入的点云中选取局部特征球中心点的点集。
分组层根据这些中心点寻找邻域来构建局部区域点集。
有两种确定邻域的方法:Ball Query查找中心点半径内的所有点,kNN查找固定数量的邻域。Ball Query保证了固定的区域比例,因此对于类似语义点标记的局部模式识别任务更好。
特征提取层通过小型pointnet网络进行卷积和pooling,得到的特征作为中心点的特征,将这些局部特征编码成特征向量。
这样层数加深后,得到的中心点个数越来越少,但每个中心点包含的信息越来越多。
(problem:计算出的特征只赋给中心点吗?邻域里其他的点要不要也加权计算后的特征呢?)
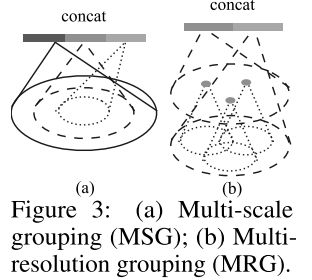
2. 密度适应:
提出了两种密度适应层来分组局部特征并且组合这些特征。
- 多尺度分组 MSG(multi-scale grouping)
是直观且简单的方法,用ramdom input dropout对输入点云进行抛弃,得到不同尺度的采样,并经过set abstraction后将这些采样层的的多尺度特征联合。 - 多分辨率分组 MRG(multi-resolution grouping)
MSG由于要对每个中心点跑大规模邻域的特征提取,计算开销很高。尤其是在low level上中心点的个数很多,时间成本很高。
因此提出多分辨率分组的方法。如图所示,新特征通过两部分连接起来,左边是通过一个set abstraction得到的特征向量,右边是用一个PointNet直接处理所有局部区域点得到的特征向量。点云密度不均时,可以通过判断当前局部区域的密度给左右两个特征向量不同权重。
分割网络
分割网络的实现思想是将点云提取一个全局的特征之后,再通过全局的特征逐步上采样。
最简单的是广播复制Broadcasting,即将每个点的附近的点的特征都变成和这个点一样,但是这样的方法会使得没有办法处理一些范围相冲突的点,或者范围没有覆盖到的点。
因此在论文中作者采用的是线性插值的方法去做特征传播,k近邻反距离加权法(inverse distance weighted average)距离越远的点权重越小。
代码中p=2, k=3。
数据集
MNIST(2D物体)
ModelNet40(3D刚性物体)
SHREC15(3D非刚性物体)
ScanNet(真实3D室内场景)
结果
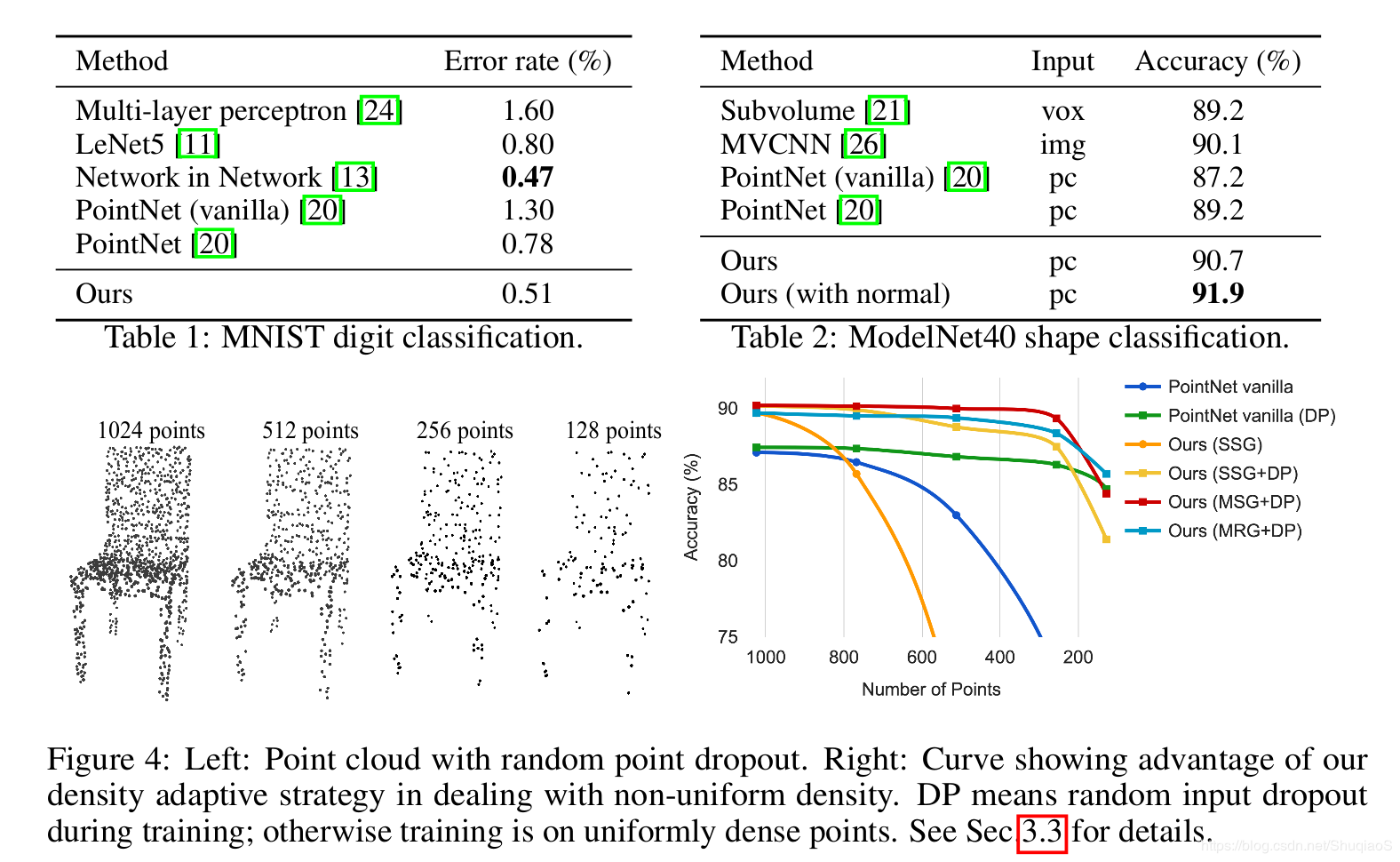
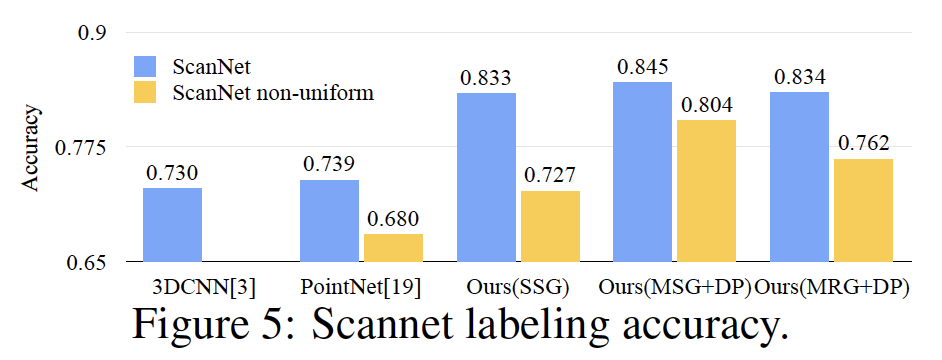
MRG没有MSG效果好,但是MSG计算复杂度很高