《PointConv: Deep Convolutional Networks on 3D Point Clouds》 CVPR 2019
Author: Wenxuan Wu, Zhongang Qi, Li Fuxin
From: CORIS Institute, Oregon State University
paper地址:
https://arxiv.org/pdf/1811.07246.pdf
源码地址:tensorflow版本 pytorch版本
简介
提出一种应用在点云上的卷积方式PointConv,让给定点的权重通过MLP网络和核密度估计函数进行学习。并且同时给出了PointConv的反卷积版本,在数据集ModelNet40,ShapeNet和Scannet进行实验表明,PointConv在点云分类、点云语义分割任务上都达到了与SOTA相当的效果,ModelNet-40分类任务上同CVPR 2019的RSCNN精度更高93.6% vs 92.5%(PointConv)。
将CIFAR-10数据集转换成点云,用PointConv做分类能与二维方法取得的效果近似。
贡献点
- 提出一个用局部邻域点坐标学权重和密度函数的非线性函数的卷积核,能够模拟3D连续卷积。
- 用求和技术提出了高效计算权重函数的网络,能够扩展到深的网络以提高性能。
- 根据PointConv做了一个反卷积版本PointDeconv,以得到更好的分割结果。
网络
整体网络结构
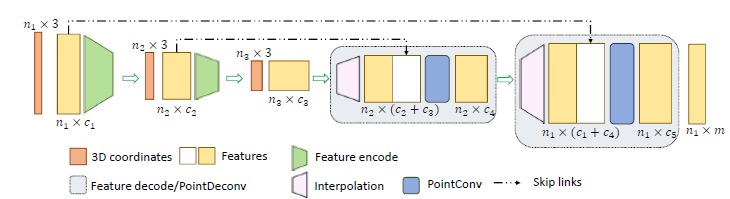
和PointNet++类似,是一个多次层的叠加结构,每一个模块由 sampling layer, grouping layer and PointConv组成,也就是说,先选择一些中心点,然后把使用这些中心点把点云分成一个个小的区域,然后对每一个区域进行特征提取,输出特征向量。
在特征提取的时候,PointNet++用的是PointNet,而本文用的是PointConv。
PointConv层设计
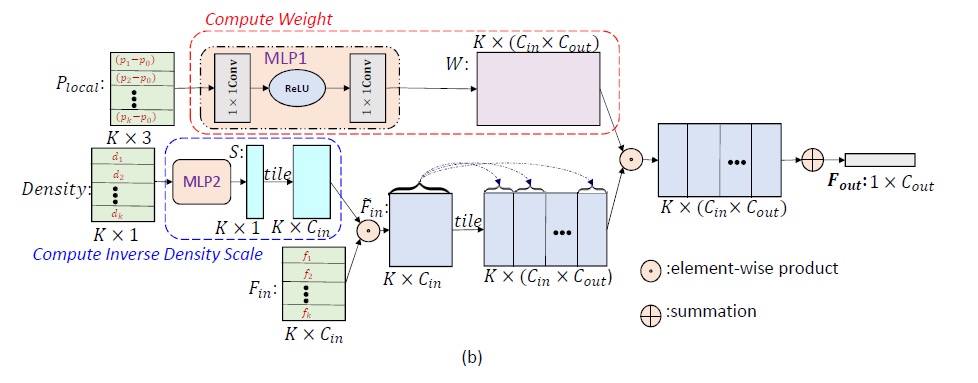
输入position vector(x, y, z)和feature(color, surface normal等)
主要增加了反密度函数(蓝色部分)和权重极端(红色部分)。
用蒙特卡罗近似去算密度函数,然后1/本身让它变成反密度函数,然后用一个MLP做非线性变换,再与feature点乘。
蒙特卡罗近似的方法是SIGGRAPH Asia论文《 Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds》提出的,用Monte Carlo对不均匀3D点云做卷积学习分布。
函数W的输入是以(x,y,z)为中心的3D邻域的点的相对坐标,输出是每个点对应的特征F的权重。对于点云,每个局部区域共享相同的权重函数,这些可以通过MLP学习得到。但不同点处的权重函数计算出的权重是不同的。
点云上的3D卷积: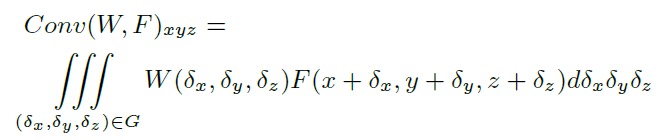
PointConv提出的3D卷积: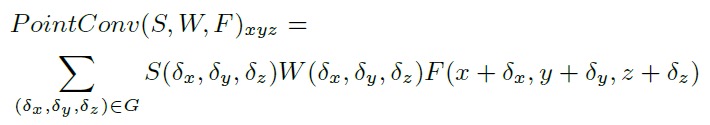
这里的S表示反密度系数函数,权重函数W可以用多层感知机MLP近似。
反卷积的特征传播
PointNet++里用的是distance-based插值方法,没有考虑到局部点云稀疏性的问题。因此作者提出了PointDeconv网络层作为反卷积操作。
PointConv主要由两部分组成:插值和PointConv。
首先通过前一层的3个最近的点,线性插值feature,与用skip link得到的卷积层里相同分辨率的feature相加。
然后把PointConv用到相加后的feature去得到高精度的特征值。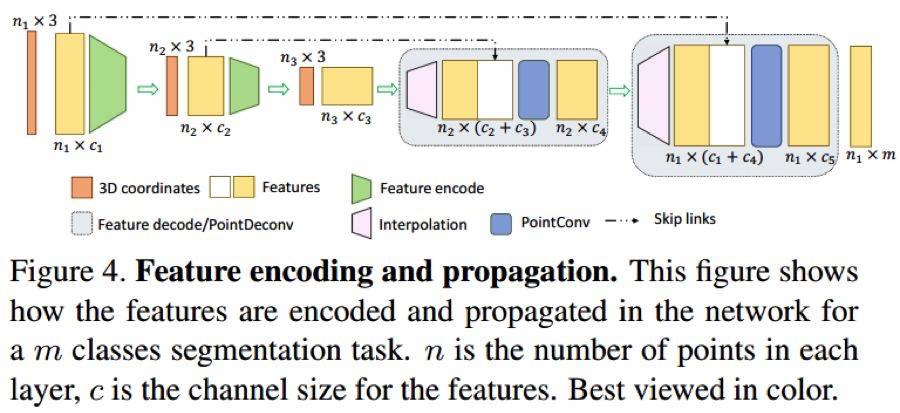
高效PointConv
最初版本的PointConv内存消耗大,效率低。
为了解决这些问题,我们提出了一种新型重构方法,将 PointConv简化为两个标准操作:矩阵乘法和2D卷积。这个新技巧不仅利用了GPU的并行计算优势,还可以通过主流深度学习框架轻松实现。由于逆密度尺度没有这样的内存问题,所以下面的讨论主要集中在权重函数W上。
内存问题产生的原因:
令B为训练阶段的mini-batch大小,N为点云中的点数,K为每个局部区域的点数,C_in为输入通道数,C_out为输出通道数。
由 MLP 生成的权重参数张量的尺寸B×N×K×(C_in×C_out)。假设B = 32,N = 512,K = 32,C_in = 64,C_out = 64,并且权重参数以单精度存储,一层网络则需要 8GB 的内存。如此高的内存消耗将使网络很难训练。

作者证明了原来PointConv中weight点乘density feature再summation等于 S点乘F_in再叉乘M,再与1x1卷积。
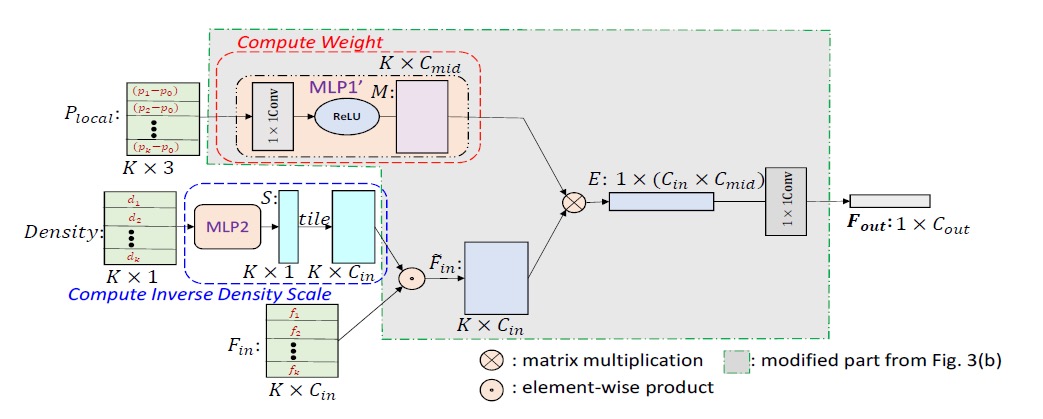
这样将原来的权重filter分成了中间结果M和卷积核H,内存占用减到了C_mid / (K X C_out)。
重新实现PointConv后,可实现完全相同的卷积操作,但大大减少内存消耗。采用相同的配置,单层卷积操作的内存占用将由 8G 缩小为 0.1G 左右,变为原来的 1/64.
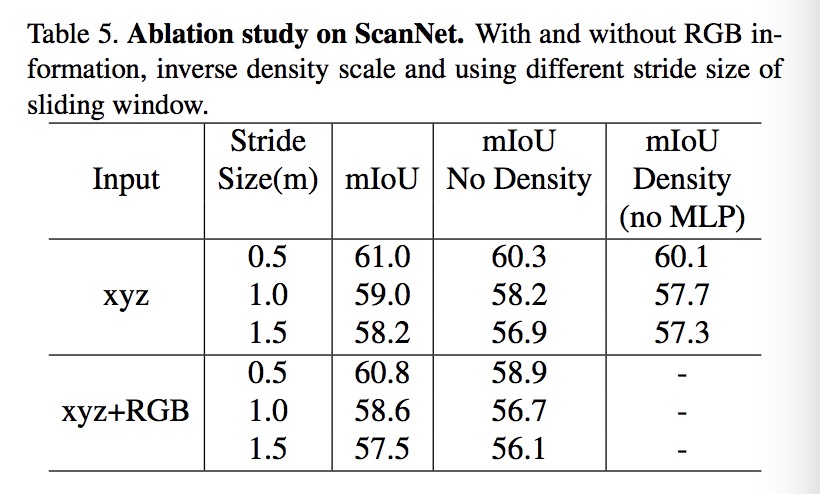
Ablation study
在ShapeNet上的分割实验,可以看到使用反密度函数基本上只提升了一个百分点。
这说明PointConv层里学习p的权重W,与特征concatenation再summation的部分比单纯的max pooling的提升很多。